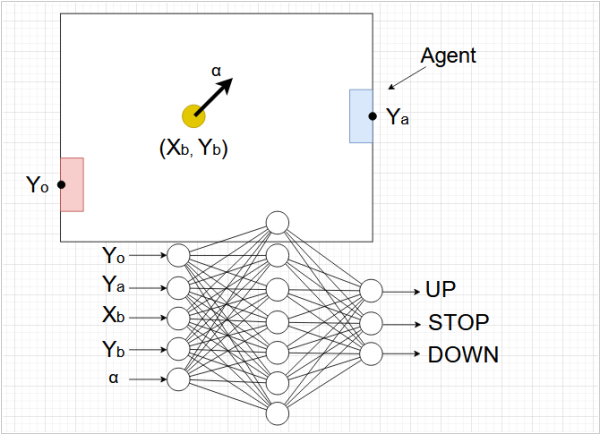
Imagine, an agent is playing Pong - moving a paddle up and down, hitting a ball. The agent's neural network receives ball's coordinates, its velocity, rival coordinate and its own coordinate as input. And it has three prediction-outputs: Up, Stop and Down.
The essence of Q-learning is that we introduce rewards for certain actions/achievements of the agent (for example, +10 for hitting a ball and -10 for missing it). We train the agent's neural network so that at each output it produces a prediction - how many points (Q) it will earn by the end of the game if it chooses a given action. After making the prediction, the agent undertakes the action that promises most points.
It's important to understand that the Q value at a given step is a prediction of how many points will be earned from the current step until the end of the game. Everything that happened before this (including the reward just received) is forgotten.
Imagine, that at a given step the agent predicts the following Q-rewards: Up=100, Stop=45, Down=15. Okay, of course, we choose the Up step. And let's say we see that if the agent steps Up, it will hit the ball and earn +10 points. Then we (in mind) step Up and find the Q predictions for the next step. Let's say they are Up=76, Stop=98, Down=16. So, Stop=98 wins. Then we tell the agent: "Look, you're currently estimating the total reward Q = 100. But at the next step, you'll get +10 and you'll estimate the remaining reward at 98 (and then you'll have a better view). So, right now, it would be more correct to estimate the remaining reward as Q = 98 + 10 = 108. So, your error now is 108 - 100 = 8."
And we backpropagate the error along the output that produced 100.
Next time in a similar situation, the agent will estimate Q closer to 108 and at the next step - 98, so the error will be almost zero.
Now let's imagine what happens when the agent doesn't hit the ball. Let's say at the pre-last step, the agent predicts Up = 23, Stop = 12, Down = 42. So, Down = 42 wins. We move down. Lose. Penalty -10. We tell the agent: "You're currently predicting that you'll earn 42 points by the end of the game. But at the next step, you'll firstly get a penalty of -10 and secondly, you'll definitely earn nothing further, meaning at the next step, Q = 0." So, it would be more correct for you to now estimate the remaining reward as Q = -10. So, your error is -10 - 42 = -52."
And we backpropagate the error to the output that produced 42.
Here are some good books about Q-learning:
Multi-Agent Reinforcement Learning: Foundations and Modern Approaches
2024 by Stefano V. Albrecht, Filippos Christianos, Lukas Schefer

Download PDF
Computational Theories of Interaction and Agency
1996 by Philip Agre, Stanley J. Rosenschein

Download PDF
Deep Reinforcement Learning: Frontiers of Artificial Intelligence
2019 by Mohit Sewak

Download PDF
See also: Top 10 eBook Organizers
How to download PDF:
1. Install Gooreader
2. Enter Book ID to the search box and press Enter
3. Click "Download Book" icon and select PDF*
* - note that for yellow books only preview pages are downloaded

